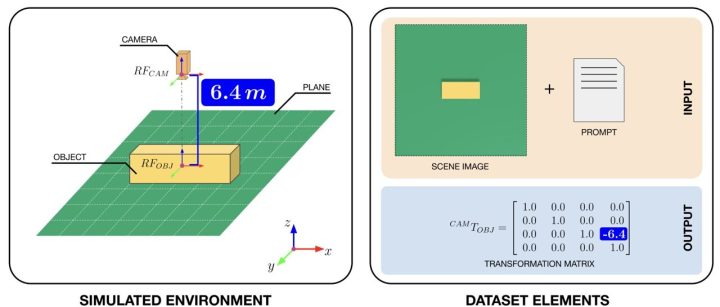
Vision-language models (VLMs) are advanced computational techniques designed to process both images and written texts, making predictions accordingly. Among other things, these models could be used to …
Vision-language models gain spatial reasoning skills through artificial worlds and 3D scene descriptions