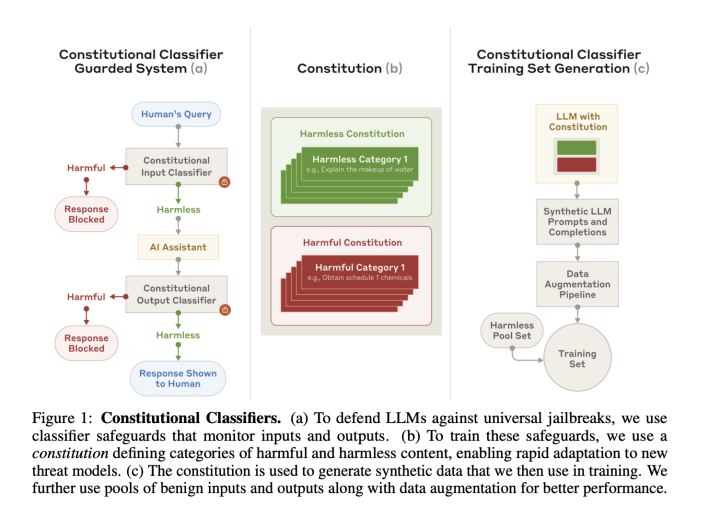
Large language models (LLMs) have become an integral part of various applications, but they remain vulnerable to exploitation. A key concern is the emergence of universal jailbreaks—prompting techniques that bypass safeguards, allowing users to access restricted information. These exploits can be used to facilitate harmful activities, such as synthesizing illegal substances or evading cybersecurity measures. As AI capabilities advance, so too do the methods used to manipulate them, underscoring the need for reliable safeguards that balance security with practical usability. To mitigate these risks, Anthropic researchers introduce Constitutional Classifiers, a structured framework designed to enhance LLM safety. These classifiers are
Anthropic Introduces Constitutional Classifiers: A Measured AI Approach to Defending Against Universal Jailbreaks