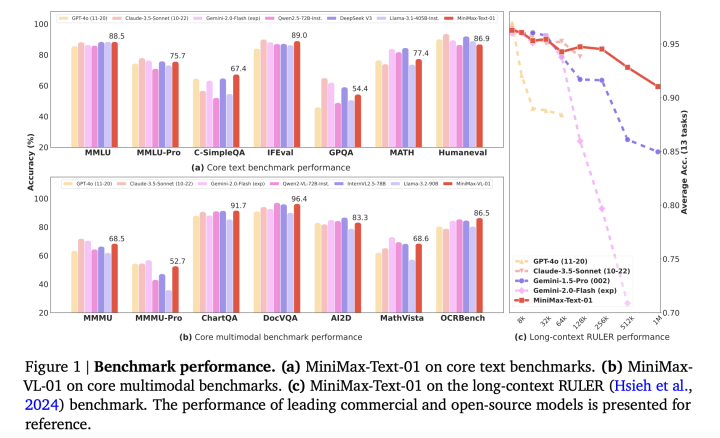
Large Language Models (LLMs) and Vision-Language Models (VLMs) transform natural language understanding, multimodal integration, and complex reasoning tasks. Yet, one critical limitation remains: current models cannot efficiently handle extremely large contexts. This challenge has prompted researchers to explore new methods and architectures to improve these models’ scalability, efficiency, and performance. Existing models typically support token context lengths between 32,000 and 256,000, which limits their ability to handle scenarios requiring larger context windows, such as extended programming instructions or multi-step reasoning tasks. Increasing context sizes is computationally expensive due to the quadratic complexity of traditional softmax attention mechanisms. Researchers have explored
MiniMax-Text-01 and MiniMax-VL-01 Released: Scalable Models with Lightning Attention, 456B Parameters, 4B Token Contexts, and State-of-the-Art Accuracy