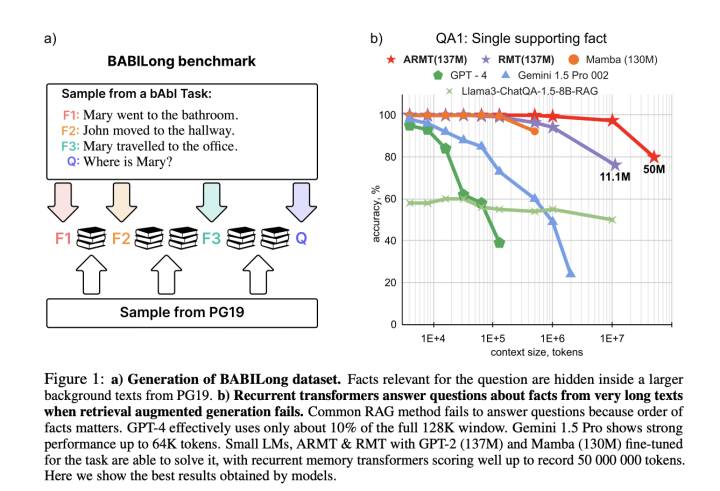
Large Language Models (LLMs) and neural architectures have significantly advanced capabilities, particularly in processing longer contexts. These improvements have profound implications for various applications. Enhanced context handling enables models to generate more accurate and contextually relevant responses by utilizing comprehensive information. The expanded context capacity has significantly strengthened in-context learning capabilities, allowing models to utilize more examples and follow complex instructions effectively. Despite these technological leaps, evaluation benchmarks have not evolved correspondingly. Current assessment tools like Longbench and L-Eval remain limited to 40,000 tokens. At the same time, modern models can process hundreds of thousands or even millions of tokens,
Scaling Language Model Evaluation: From Thousands to Millions of Tokens with BABILong