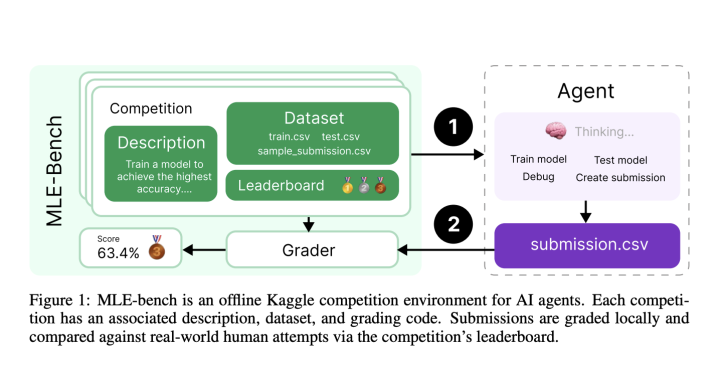
Machine Learning (ML) models have shown promising results in various coding tasks, but there remains a gap in effectively benchmarking AI agents’ capabilities in ML engineering. Existing coding benchmarks primarily evaluate isolated coding skills without holistically measuring the ability to perform complex ML tasks, such as data preparation, model training, and debugging. OpenAI Researchers Introduce MLE-bench To address this gap, OpenAI researchers have developed MLE-bench, a comprehensive benchmark that evaluates AI agents on a wide array of ML engineering challenges inspired by real-world scenarios. MLE-bench is a novel benchmark aimed at evaluating how well AI agents can perform end-to-end machine
OpenAI Researchers Introduce MLE-bench: A New Benchmark for Measuring How Well AI Agents Perform at Machine Learning Engineering