Language models (LMs) have become fundamental in natural language processing (NLP), enabling text generation, translation, and sentiment analysis tasks. These models demand vast amounts of training data to function accurately and efficiently. However, the quality and curation of these datasets are critical to the performance of LMs. This field focuses on refining the data collection and preparation methods to enhance the models’ effectiveness. A significant challenge in developing effective language models is improving training datasets. High-quality datasets are essential for training models that generalize well across various tasks, but creating such datasets is complex. It involves filtering out irrelevant or
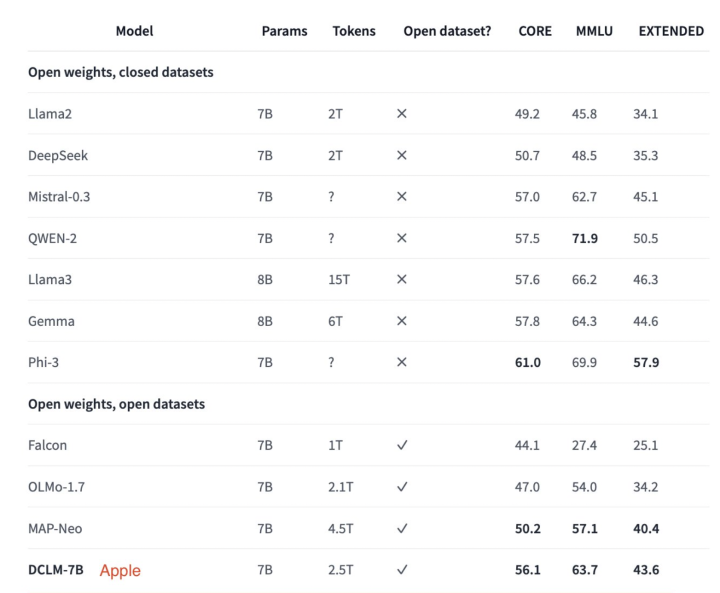
Apple AI Released a 7B Open-Source Language Model Trained on 2.5T Tokens on Open Datasets